|
|
|
My research focuses on the intersection of machine learning and systems, with particular emphasis on:
|
|
My primary focus at ADSL is LinuxGuard, a pipeline that learns from Linux kernel bug fixes to generate custom clang-tidy checkers. By mining commit history, the system builds AST matchers that flag unchecked error paths across kernels v3.0 through v6.0, turning each fixed vulnerability into a proactive safeguard.
|
|
As a remote research intern at WukLab, I work with Professor Yiying Zhang on two complementary threads at the LLM-systems interface: using LLMs to produce better low-level code, and using systems measurement to understand what really limits LLM serving on commodity edge hardware. |
|
Xuming Huang, advised by Yiying Zhang — WukLab, UC San Diego 2025–present · Ongoing Building an agent loop that takes a reference kernel, proposes compiler-grade transformations (vectorization, tiling, register-pressure reduction), then verifies each candidate by running it against the original and benchmarking the survivors. The goal: close the gap between LLM-suggested code edits and the kind of optimizations a production compiler engineer would accept.
|
|
Xuming Huang, advised by Yiying Zhang — WukLab, UC San Diego 2025–present · Ongoing
A measurement-first study of what actually governs latency for agentic LLMs running entirely on-device.
We drive
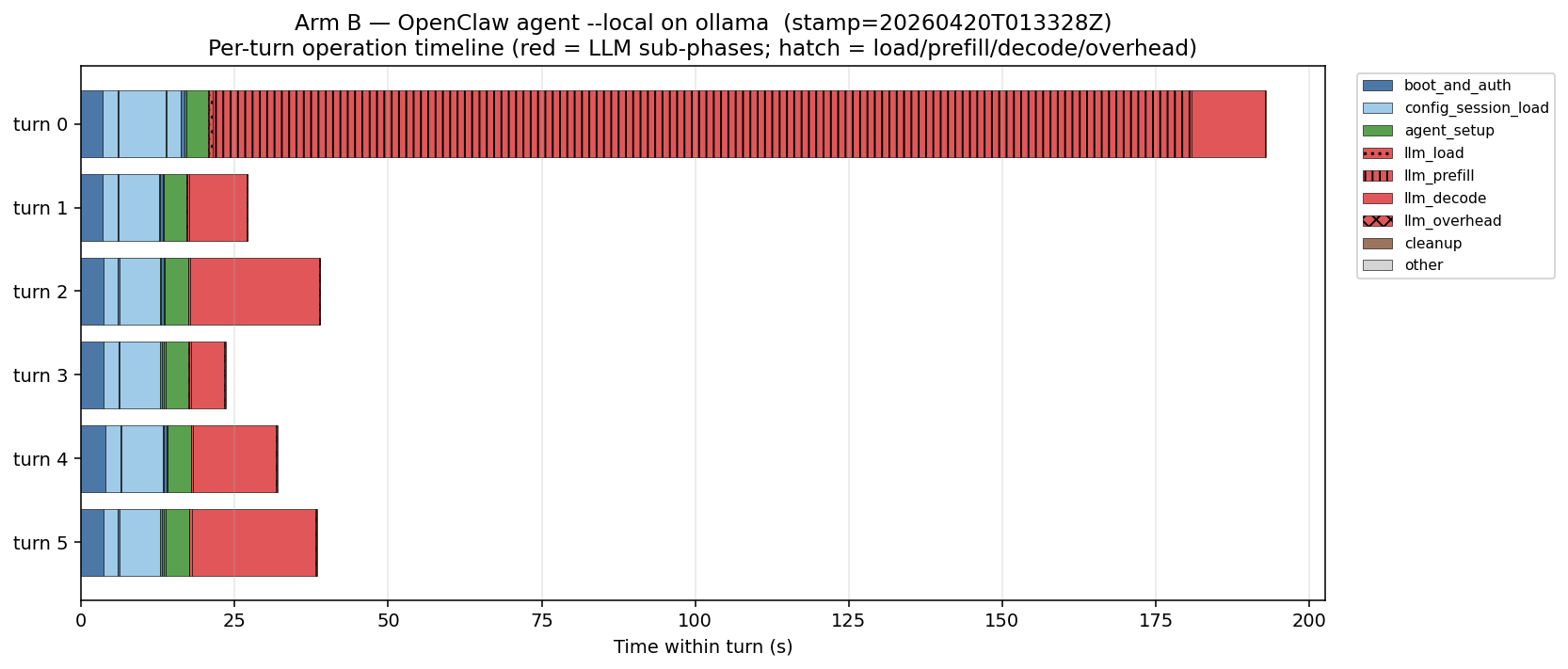
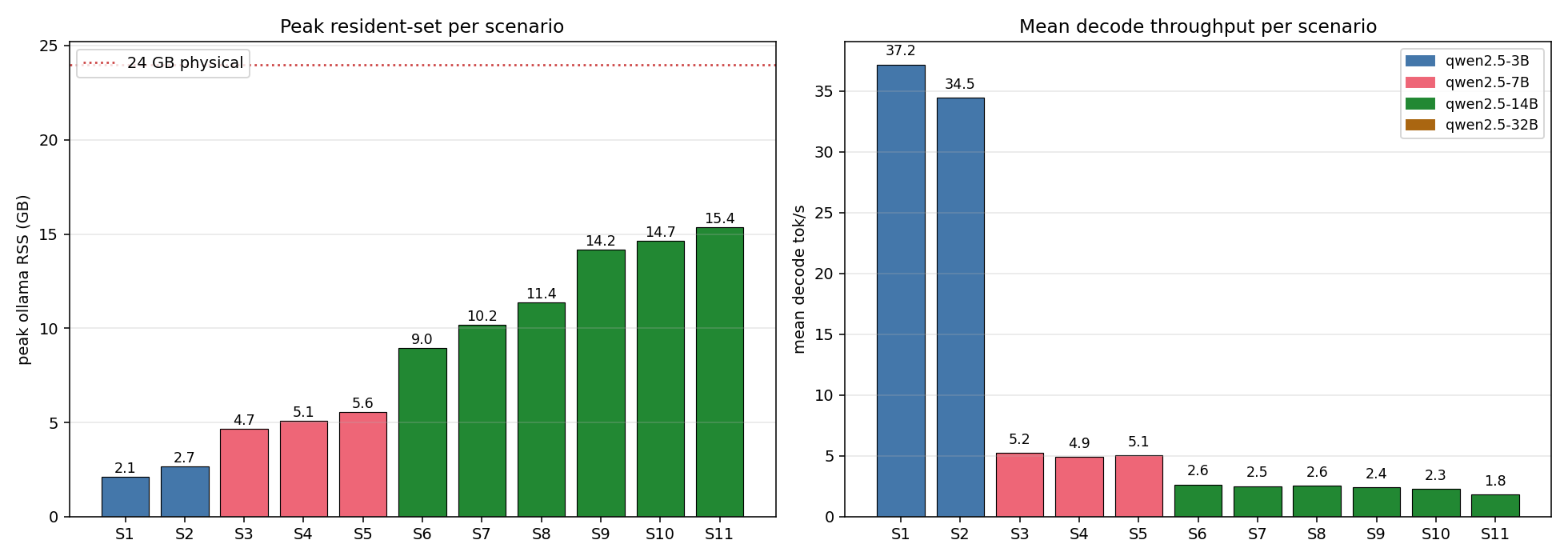
Current phase: running the full 361-task OSWorld-Verified benchmark with Holo3-35B-A3B — the #1 open-weight computer-use model — served entirely on an Intel Panther Lake NUC (96 GB unified, CPU-only llama.cpp after measured GPU/NPU bring-up), replicating the official leaderboard config (100-step budget, screenshot-only) with per-step latency, token, KV-cache and 5-domain RAPL energy profiling.
[🔴 Live benchmark tracker] [📊 Profiling corpus & schema] [⚡ KV-cache & iGPU study] [🖥 iGPU & NPU bring-up] [📊 Beyond-OSWorld leaderboard check] [🔋 Inference energy profile] [⚡ Operator-level energy microbench] [🧠 Holo1.5 prefill-offload & memory wall] [⚙ NPU compile-time profiling] [📈 NPU Compilation Optimization (multi-family + precision)] [Interactive workflow demo] [Memory hierarchy demo] |
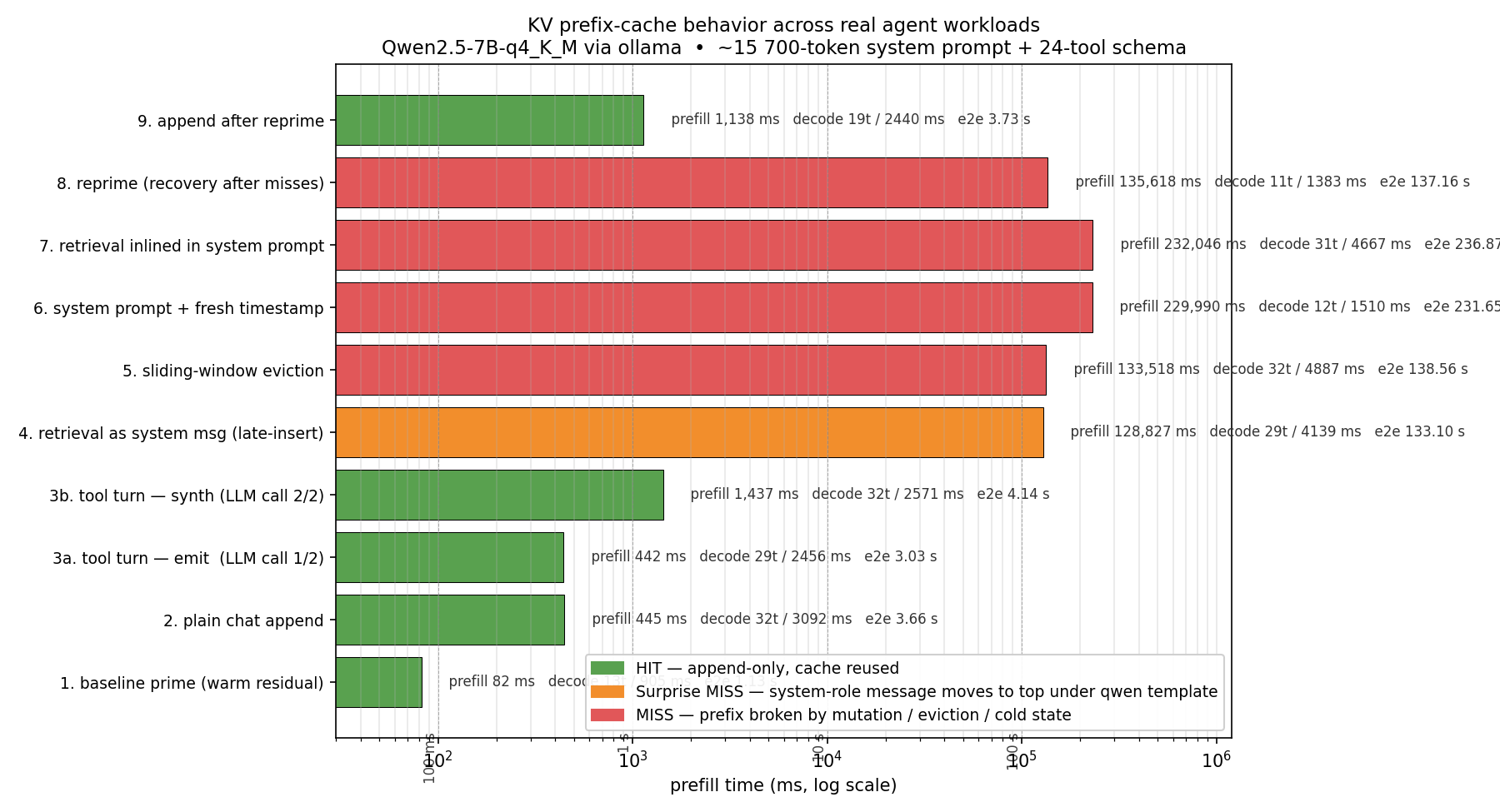
KV prefix-cache hit / miss / surprise-miss behavior across 8 OpenClaw workloads. Auto-compaction (scenario 8) drives the longest prefill bar. |
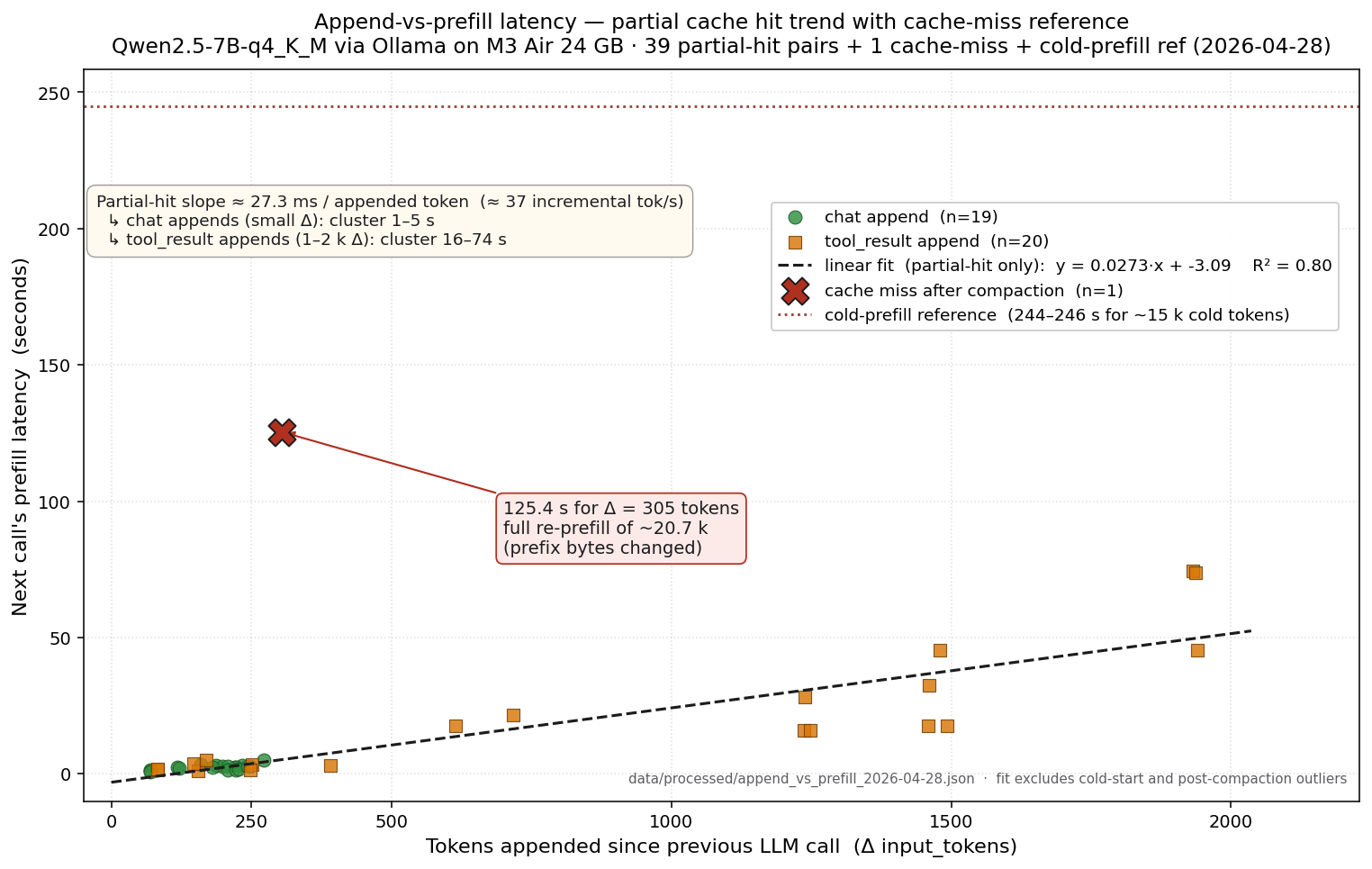
Append-token count vs. next call's prefill latency across 39 partial-hit data points — the cache-miss event sits ~24× off the trend. |
|
Representative projects are highlighted. See also my Google Scholar profile. |
|
Feel free to clone my template Xuming Huang |